
Redis Mastery: Why It’s the Secret Weapon of High-Performance Backend Systems
In the world of modern software engineering, speed isn’t just a luxury—it’s a survival requirement. As user expectations shift toward “instant” interactions, the traditional database-first approach often becomes the very bottleneck that stifles scalability. Enter Redis.
Originally an acronym for REmote DIctionary Server, Redis has evolved from a simple caching tool into a versatile, multi-model data store that powers the world’s most demanding applications. Whether you are building a real-time leaderboard, a session manager for millions of users, or a complex microservices orchestrator, understanding Redis is no longer optional for a Senior Backend Engineer; it is essential.
In this comprehensive guide, we will dive deep into the mechanics of Redis, explore its unique data structures, and analyze how it fits into the modern architectural stack.
What Makes Redis Special?
Most developers know Redis as a “cache,” but that description barely scratches the surface. To understand why it’s so popular, we must look at its core philosophy.
1. The In-Memory Advantage
Unlike traditional databases like MySQL or PostgreSQL, which store data primarily on disk (HDD or SSD), Redis keeps all its data in the system’s RAM.
Because RAM access is orders of magnitude faster than disk I/O, Redis can perform hundreds of thousands of operations per second with sub-millisecond latency. While a disk-based database might take 10-50ms to return a query, Redis typically responds in less than 1ms.
2. Single-Threaded but Ultra-Fast
A common point of confusion is Redis’s single-threaded nature. How can a single thread be faster than multi-threaded databases?
- No context switching: The CPU doesn’t waste time swapping between threads.
- No locking overhead: Since there’s only one thread, there’s no need for complex locking mechanisms or mutexes to prevent data corruption.
- I/O Multiplexing: Redis uses non-blocking I/O to handle thousands of concurrent connections efficiently.
3. Versatile Persistence
Despite being in-memory, Redis isn’t “volatile” by default. It offers two main persistence options:
- RDB (Redis Database): Takes point-in-time snapshots of your dataset at specified intervals.
- AOF (Append Only File): Logs every write operation received by the server, allowing for a full reconstruction of the data.
Core Data Structures in Redis
One of the primary reasons Redis stands out is that it isn’t just a “string” store. It supports a rich variety of data structures that allow developers to map complex application logic directly into the database.
1. Strings
The most basic type. A string can store anything from a simple text value to serialized JSON or even binary data (up to 512MB).
- Use Case: Simple caching of HTML pages or API responses.
- Command Example:
SET user:100 "John Doe"
2. Lists
Lists are simply collections of strings, sorted by insertion order. They are implemented as linked lists, making head and tail operations extremely fast.
- Use Case: Building a simple message queue or a “recent activity” feed.
- Command Example:
LPUSH tasks "process_image"
3. Hashes
Hashes are maps between string fields and string values. They are the perfect data structure to represent objects.
- Use Case: Storing user profiles (e.g., name, email, age) as a single key.
- Command Example:
HSET user:100 name "Alice" email "alice@example.com"
4. Sets
Sets are unordered collections of unique strings. Redis allows you to perform set operations like intersections, unions, and differences.
- Use Case: Tracking unique visitors to a website or identifying mutual friends in a social network.
- Command Example:
SADD tags "golang" "redis" "backend"
5. Sorted Sets (ZSets)
Similar to Sets, but every member is associated with a score. Members are kept ordered by their score.
- Use Case: Real-time gaming leaderboards or prioritized task queues.
- Command Example:
ZADD leaderboard 1500 "PlayerOne"
Real-World Use Cases: Beyond Basic Caching
While caching is the “Hello World” of Redis, its real power is seen in more complex scenarios.
Caching
The most obvious use case. By storing frequently accessed data in Redis, you reduce the load on your primary database and significantly improve application response times.
Session Storage
In a distributed system, you cannot store user sessions in the memory of a single application server (as that server might scale down or restart). Redis serves as a centralized, fast, and persistent store for session data, ensuring a seamless user experience across multiple server nodes.
Rate Limiting
Preventing API abuse is critical. Using Redis’s atomic increments (INCR) and time-to-live (TTL) features, you can easily implement a sliding-window rate limiter that tracks how many requests an IP address has made in the last minute.
Message Queues
Using the List or Stream data structures, Redis can act as a lightweight message broker. While not as feature-rich as RabbitMQ or Kafka, it is incredibly easy to set up for simple producer-consumer patterns.
Real-time Analytics
Because Redis operations are atomic, it is perfect for counting events in real-time. Whether it’s page views, ad clicks, or error rates, you can increment counters in Redis without worrying about race conditions.
Redis vs. Traditional Databases
Should you replace MySQL with Redis? No. They serve different purposes.
| Feature | Redis | MySQL / PostgreSQL |
| Storage Medium | RAM (Primary), Disk (Secondary) | Disk (Primary), RAM (Cache) |
| Performance | Extremely High (Sub-ms) | High (Millisecond range) |
| Data Structure | Key-Value / Specialized | Relational (Tables/Rows) |
| Scalability | Easy Horizontal Scaling (Cluster) | Complex Sharding / Replication |
| Best For | Transient, high-speed data | Complex queries, ACID compliance |
When to use Redis: When speed is more important than complex relational queries.
When to use MySQL: When you need to perform complex JOIN operations and ensure strict data integrity for long-term storage.
Redis in Modern Architectures
In a modern, scalable backend, Redis usually sits between the application logic and the permanent data store.
The Microservices Context
In a microservices architecture, Redis often acts as the “State Store.” Since microservices are designed to be stateless, any state they need to maintain (like a temporary calculation or a user’s progress in a multi-step form) is pushed to Redis.
High-Traffic Resilience
During traffic spikes (like a Black Friday sale), your relational database might struggle under the weight of thousands of read requests. By implementing a Cache-Aside pattern, Redis handles the bulk of the read traffic, protecting your primary database from crashing.
Distributed Systems
Redis provides primitives for Distributed Locking. If you have multiple background workers trying to process the same file, you can use Redis to ensure only one worker “acquires the lock” at a time, preventing duplicate processing.
Essential Redis Commands for Every Developer
If you’re starting with Redis, these are the commands you’ll use 90% of the time.
# 1. Basic Key-Value Operations
SET session:user:123 "active"
GET session:user:123
EXPIRE session:user:123 3600 # Key expires in 1 hour
# 2. Working with Hashes (Objects)
HSET product:99 name "Mechanical Keyboard" price 120
HGETALL product:99
# 3. List Operations (Queues)
LPUSH incoming_emails "email_1@test.com"
RPOP incoming_emails
# 4. Atomic Increments (Counting)
INCR page_views:home_page
# 5. Sorted Sets (Leaderboards)
ZADD highscores 500 "UserA" 750 "UserB"
ZREVRANGE highscores 0 10 WITHSCORES
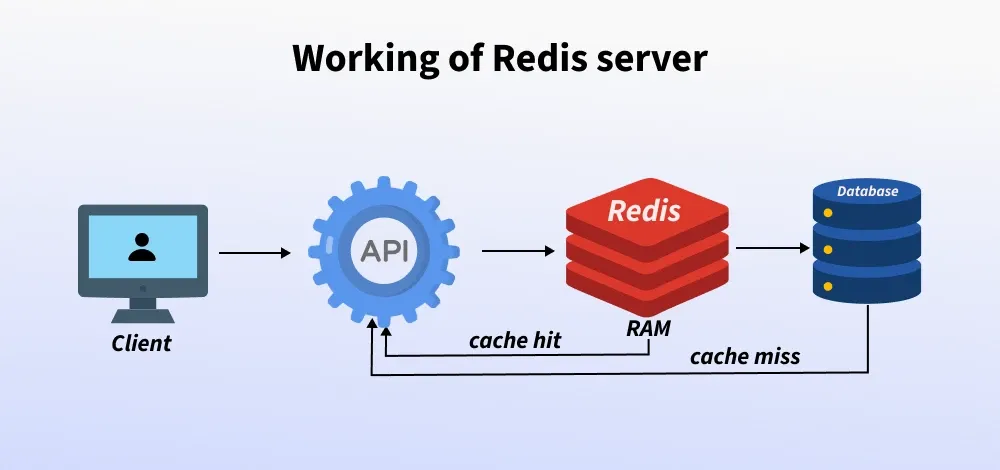
Example Architecture: The “Golden Path”
In a typical web application, the data flow looks like this:
- User Request: A user requests their profile via an API.
- API Check: The API server first checks Redis:
GET user:profile:100. - Cache Hit: If found, the data is returned immediately (Total time: ~2ms).
- Cache Miss: If not found, the API queries MySQL (Total time: ~50ms).
- Update Cache: The API saves the MySQL result back to Redis with an expiration time for future requests.
Advantages and Limitations
Advantages
- Performance: Unmatched speed for read/write operations.
- Simplicity: Minimal configuration and an intuitive API.
- Rich Ecosystem: Native clients for almost every programming language (Node.js, Python, Go, PHP, etc.).
- High Availability: Supported through Redis Sentinel and Redis Cluster.
Limitations
- Memory Cost: RAM is significantly more expensive than disk storage. You must be selective about what you store.
- Data Loss Risk: Because it’s in-memory, an improper shutdown could result in some data loss if persistence isn’t configured correctly.
- No Complex Queries: You cannot perform SQL-style
WHEREclauses across different data types easily.
Conclusion
Redis is much more than a simple cache; it is a fundamental building block of the modern internet. By moving performance-critical data into memory and leveraging specialized data structures, backend engineers can build systems that are not only faster but also more resilient and easier to scale.
Whether you are optimizing a legacy monolith or architecting a cutting-edge microservices platform, Redis belongs in your toolkit. Start small with basic caching, and as you grow, explore the power of Streams and Sorted Sets to unlock the full potential of your application.